今回は、pythonを使ったスクレイピングの実践的な方法を紹介します。実際にスクレイピングする機会があり、調査した情報をまとめたものです。これくらい覚えておけば、ある程度のスクレイピングは実行できると思います。

環境構築
python3をインストールし、スクレイピングに必要なモジュールを導入します。
pip install requests beautifulsoup4 lxmlpythonファイルの先頭には以下を記述し、モジュールをロードすればライブラリを呼び出すことができます。
import requests
from bs4 import BeautifulSoup小技集
HTMLを丸ごと保存する
HTMLファイルを丸ごと保存する場合、requestsのcontent属性をバイナリ形式で保存すると、エンコードの影響を考慮しなくて委もよいため便利です。
s = requests.get('http://sample.local')
with open('filename', mode='wb') as f:
f.write(s.content)エンコードを調整する
HTMLデータのテキストを使用する場合、requestの属性に対して、エンコードを指定しておきます。これは、requestsがたまにエンコードを誤判定している場合があるため、HTMLの指定型を再指定しておきます。EUC-JPで謎のエラーに困ったときに対策したものです。
s = requests.get('http://sample.local')
s.encoding = s.apparent_encoding
html_data = s.textノードを抽出する
ノード抽出にはBeautifulSoupのselect関数でCSSセレクタを使うと便利です。条件に指定できるのは、タグや属性のみでテキスト等の値はできません。下記の例だと、classに”xx yy”を持つdlタグ子孫のddタグ直下にあるaタグを収集します。
s = requests.get('http://sample.local')
soup = BeautifulSoup(s.text, 'lxml')
mynode = soup.select('dl[class="xx yy"] dd>a')属性値を取得する
属性値は、下記attrsで取得可能です。下記では、aタグからhrefの値を取得しています。
for x in mynode:
href_value = x.attrs['href']ノードの値を取得する
ノードが複雑で値を取り出しづらい場合、文字列関数で加工した方が早いとおもいます。replace, splitや正規表現を用います。下記の例では、’30’という部分を取り出しています。
text = '<a href="/xxxx/yyyy">30日</a>'
y = text.replace(u'<a href="/xxxx/yyyy">', '').split(u'日')[0]CSSセレクタについて
よく使いそうなCSSセレクタを取り上げます。
基本形
| div | 何もつけないと、タグ名で指定する |
| .classname | ‘.’をつけると、クラス名で指定する |
| #idname | ‘#’をつけると、id名で指定する |
要素探索
| 直下の子要素 | div>a | divの1階層したのみにあるa要素を収集します。 |
| 子孫要素 | div a | div要素の下階層全てにあるa要素を収集します。 |
| テキストフォーム | input[type=”text”] | input要素のtype=textである要素を収集します。 |
| 最初の子要素 | p:first-of-type | 同一階層のp要素の中で最初の要素を収集します。 |
| 最後の子要素 | p:last-of-type | 同一階層のp要素の中で最後の要素を収集します。 |
| 奇数の子要素 | p:nth-of-type(odd) | 同一階層のp要素の中で奇数順の要素を収集します。 |
| 偶数の子要素 | p:nth-of-type(even) | 同一階層のp要素の中で偶数順の要素を収集します。 |
| 属性が完全一致する要素 | p[class=”xxx”] | p要素の中でclass=”xxx”属性を持つ要素を収集します。 |
| 属性の一部が一致する要素 | p[class*=”xxx”] | p要素の中でclassの一部に”xxx”をもつ要素を収集します。 |
| 属性の開始が一致する要素 | p[class^=”xxx”] | p要素の中でclassの開始に”xxx”をもつ要素を収集します。 |
| 属性の最後が一致する要素 | p[class$=”xxx”] | p要素の中でclassの最後に”xxx”をもつ要素を収集します。 |
| n番目の子要素 | p:nth-of-type(n) | p要素の中でn(1~)番目に登場する要素を収集します。 |
| 後ろからn番目の子要素 | p:nth-last-of-type(n) | p要素の中で後ろからn(1~)番目に登場する要素を収集します。 |
スクレイピングサンプル
スレイピング用テストサイトWeb Scraper Test Sitesを用いて、サンプルを記載します。
![スクレイピングテストサイト]()
スクレイピングテストサイト
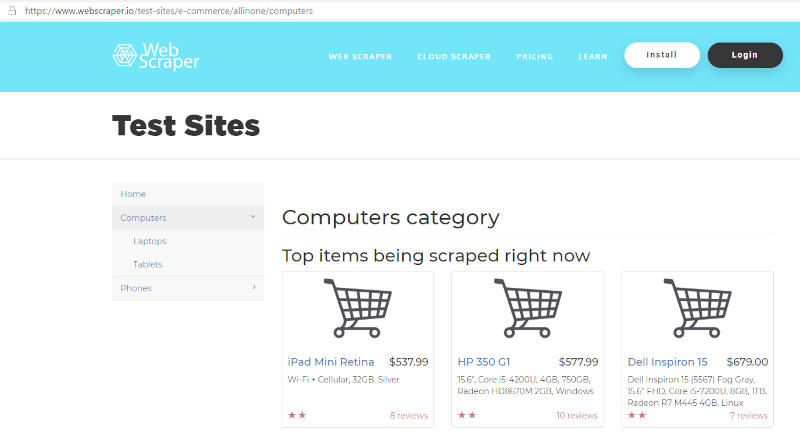
下記の例では、リンク先と値段を取得しています。
import requests
from bs4 import BeautifulSoup
s = requests.get('https://www.webscraper.io/test-sites/e-commerce/allinone/computers')
s.encoding = s.apparent_encoding
soup = BeautifulSoup(s.text, 'lxml')
# get href.
node_link = soup.select('div[class="thumbnail"] h4>a')
for x in node_link:
print('href = {0}'.format(x.attrs['href']))
# get price.
node_price = soup.select('h4[class="pull-right price"]')
for y in node_price:
print('price = {0}'.format(y.text.replace('$','')))href = /test-sites/e-commerce/allinone/product/578
href = /test-sites/e-commerce/allinone/product/621
href = /test-sites/e-commerce/allinone/product/611
price = 498.23
price = 1310.39
price = 1221.58まとめ
今更ではありますが、pythonによるするクレイピングは非常に強力です。CSSセレクタを覚えれば、活用場所がぐんと広がります。これからスクレイピングを始める方の参考になれば幸いです。
以上、pythonによるスクレイピングの紹介でした。


コメント